Table of Contents
Introduction
In this blog, we’ll discuss how we can run Ollama – the open-source Large Language Model environment – locally using our own NVIDIA GPU. In recent years, the use of AI-driven tools like Ollama has gained significant traction among developers, researchers, and enthusiasts. While cloud-based solutions are convenient, they often come with limitations such as recurring costs, data privacy concerns, and latency issues. Running Ollama on your local machine addresses these challenges, offering greater control, improved speed, and a cost-effective setup—especially when powered by NVIDIA GPUs.
What is my local workstation setup?

I have refurbished Dell Precision 3630 workstation that came with NVIDIA Quadro 2000 chip set. I was not using GPU at all but then one day idea came to my mind on using this GPU for running opensource LLM workloads.
Tell me more about NVIDIA Quadro P2000?
The NVIDIA Quadro 2000 is a mid-range workstation GPU designed for professional applications. Here’s a concise overview of its key features and benefits:
Key Features:
- High Performance Graphics :
- Built on the Pascal architecture, providing robust graphics processing capabilities suitable for demanding graphic-intensive tasks.
- Memory and Bandwidth :
- Equipped with 5GB of GDDR5 memory, offering efficient data handling and high bandwidth for fast data transfer.
- CUDA Support :
- Fully supports CUDA for parallel computing, enabling efficient execution of compute-intensive tasks such as simulations, modeling, and data analysis.
- Display Output :
- Features a DisplayPort 1.2 output with deep color support (up to 4K at 60Hz), ensuring high-quality image transfer across multiple monitors or large resolution displays.
- Compatibility and Support :
- Comes with full NVIDIA driver support for the latest features and performance optimizations.
Using Quadro P2000 for running LLM workloads?
We need to first install NVIDIA Container Toolkit so that GPU hardware can be used for running container workloads.
As a prerequisite we have to install the NVIDIA GPU driver for our Linux distribution. These NVIDIA driverers can be installed using package manager for Linux distribution in use.
I’m currently using Ubuntu 24 as my workstation operating system. I’ll install nvidea-smi to check my GPU details.
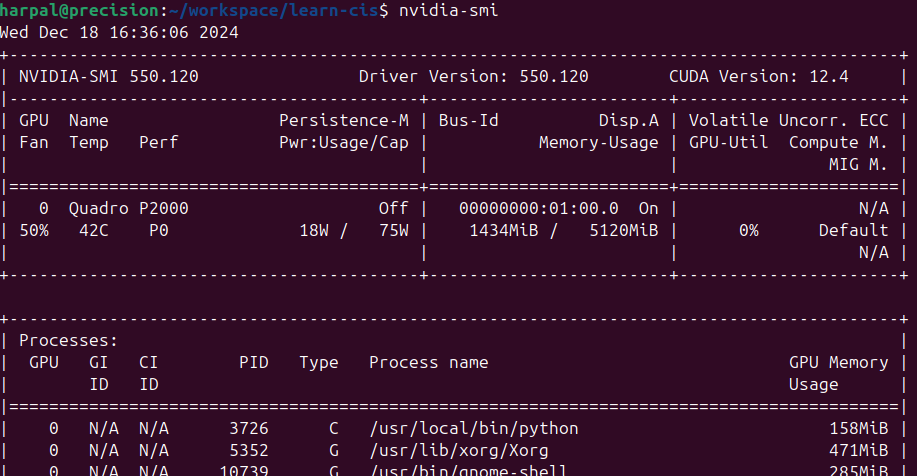
Let’s install NVIDIA Container Toolkit
The NVIDIA Container Toolkit enables users to build and run GPU-accelerated containers. The toolkit includes a container runtime library and utilities to automatically configure containers to leverage NVIDIA GPUs.
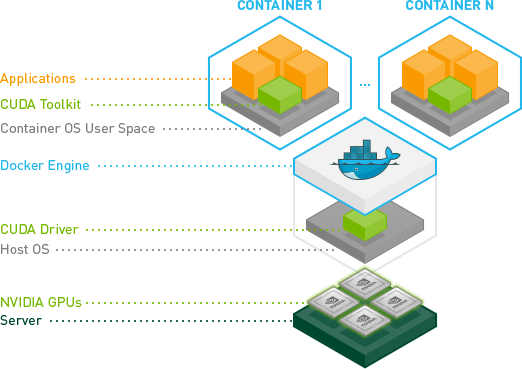
Instructions to install toolkit are given on NVIDIA website for various operating system environments.
Below instructions are for Centos/Fedora/Red Hat op[erating system:
Installing toolkit using Yum or Dnf
Configure the production repository:
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \ sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repoOptionally, configure the repository to use experimental packages:
sudo yum-config-manager --enable nvidia-container-toolkit-experimentalInstall the NVIDIA Container Toolkit packages:
sudo yum install -y nvidia-container-toolkitConfiguring Docker
Configure the container runtime by using the nvidia-ctk command:
sudo nvidia-ctk runtime configure --runtime=dockerThe nvidia-ctk command modifies the /etc/docker/daemon.json file on the host. The file is updated so that Docker can use the NVIDIA Container Runtime.
Restart the docker daemon.
$ sudo systemctl restart dockerRunning a Sample Workload with Docker
After you install and configure the toolkit and install an NVIDIA GPU Driver, you can verify your installation by running a sample workload. Example using podman and other runtimes are documented here.
Run a sample CUDA container:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smiYour output should resemble the following output:
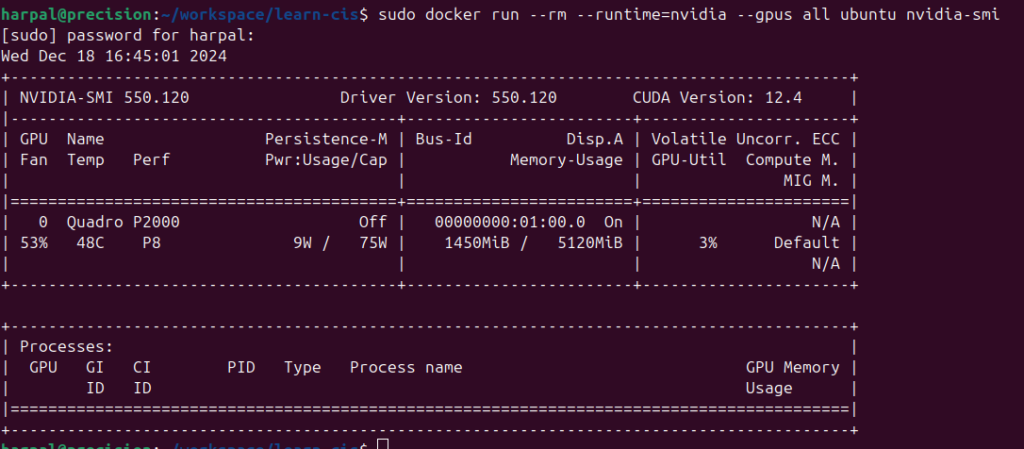
Deploying OLLAMA & Open-WebUI Containers
version: '3.8'
services:
ollama:
image: ollama/ollama
container_name: ollama
volumes:
- ollama:/root/.ollama
ports:
- "11434:11434"
restart: always
open-webui:
image: ghcr.io/open-webui/open-webui:ollama
container_name: open-webui
volumes:
- ollama:/root/.ollama
- open-webui:/app/backend/data
ports:
- "3000:8080"
restart: always
volumes:
ollama:
open-webui:Step 1: Install ollama on the host operating system using command:
curl -fsSL https://ollama.com/install.sh | shFor more details please see ollama website.
Step 2: Pull the LLM model of your choice by going to the ollama registry.

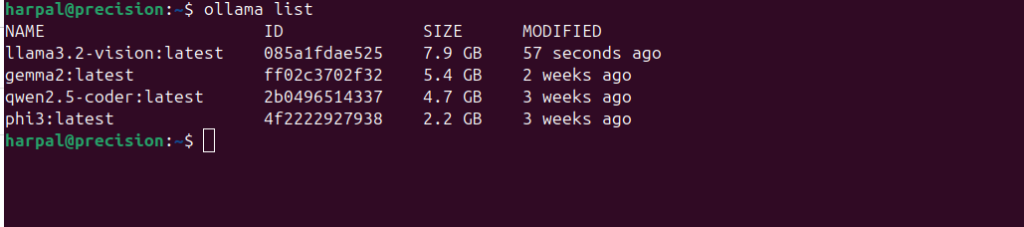
We can list all the downloaded models on the current system.
Step 3: Start the ollama serve using command:
ollama serve
You can see the ollama process in running state.
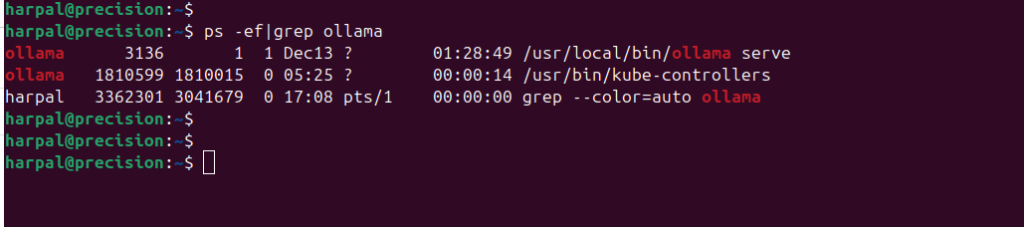
The process will bound to the tcp port: 11434

Step 4: Now run the Open Web UI which will provide us interface to these LLM Models. We will use docker image for running Open Web UI.
To run Open WebUI with Nvidia GPU support, use this command:
docker run -d -p 3000:8080 --gpus all --network=host --add-host=host.docker.internal:host-gateway -e OLLAMA_BASE_URL=http://127.0.0.1:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
For instructions on running Open Web UI please check Open Web UI website.
Web UI:
http://localhost:8080/
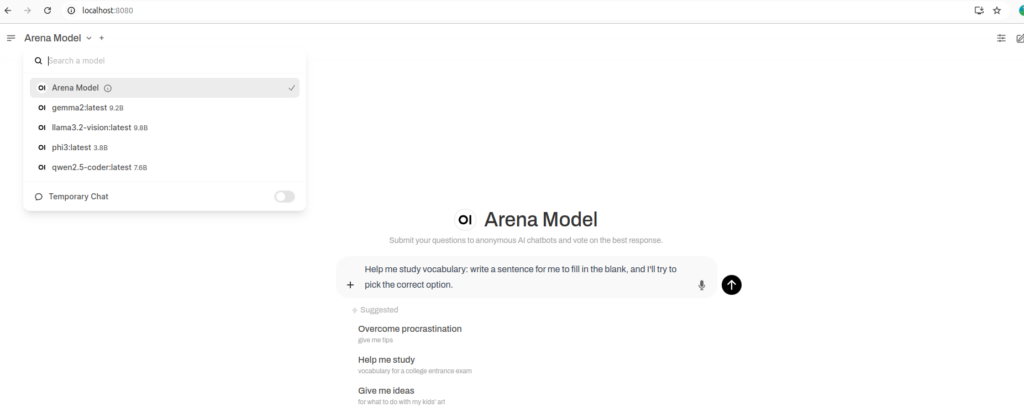
Create your account and loging and you will see this page where you can choose the LLM Model and use as you do chatGPT. The workload will be executed locally on the GPU.

We can see on submission workload getting triggerd

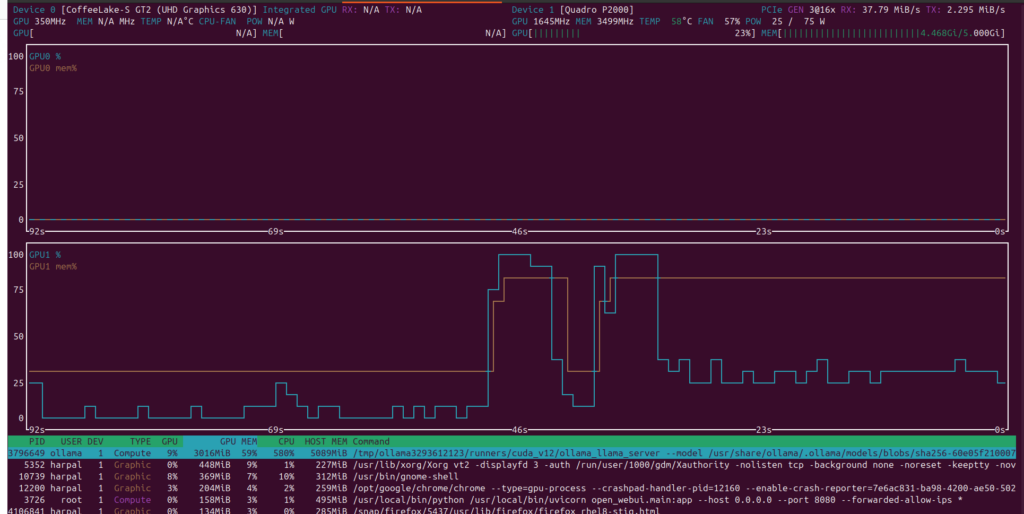
Using nvtop for realtime memory statitics for GPU workload.